Préparer un corpus de tweets avec open/google Refine pour le visualiser dans Gephi
Il existe différentes méthodes pour analyser le graphe documentaire/social issu des flux de tweets. Pegasusdata propose une méthode basée sur l'usage du logiciel de statistiques R et de la librairie Igraph dans un tutoriel réalisé par Yannick Rochat, Martin Magdinier, dans son blog dédié à la maitrise de Open/google Refine consacre plusieurs posts au traitement des tweets, dont un qui m'a longtemps servi pour manipuler les tweets sans utiliser d'expressions régulières, et un autre qui explique comment préparer les données pour Gephi. Ce que je vais présenter plus loin, n'est pas une synthèse des deux posts, et offre une autre approche toujours sous Open/ggggle Refine, la première des solutions collectées par Martin étant trop lourde parfois, et la seconde ne permettant pas de produire un fichier très élaboré, offrant simplement un graphe trop sommaire à mon goût.
Celle que je présente ici me parait être la plus simple en nombre de manipulations, et la plus efficace si l'on ne connaît rien à R / Rstudio et si l'on travaille pourtant sur un fichier comportant un très grand nombre de lignes (autour de 500.000 tweets par ex.), dans la mesure où elle est économe sur l'usage des fonctions "split into several columns" & co, et n'étouffe pas l'ordinateur sous les opérations de calcul... Elle demande d'utiliser des expressions régulières, ce qui peut déstabiliser un instant ceux qui ignorent leur existence. En fait, comme beaucoup de choses, au début ça fait peur, mais en fait c'est pas grave... Pour ma part, je n'y connais pas grand chose, mais en tâtonnant, comme souvent avec l'informatique ou les maths, j'ai trouvé les deux ou trois regex qui me facilitaient le travail. C'est l'objet de ce post, fournir les expressions qu'il suffira de copier/coller dans Open/google Refine, ceci revenant à faire à peine plus que cliquer sur un bouton qui dirait "extrait tous les hashtags pour moi steuplé" ;-)
Prérequis, récupération du corpus de tweets et ouverture dans OpenRefine
Prérequis : avoir installé Gephi, mais surtout avoir installé open/gggle refine.
Concernant l'usage d'une base de données de tweets destinée à la production d'un graphe dans Gephi, la forme du fichier à produire est simple, il suffit juste d'anticiper deux ou trois choses :
Il faut produire une table des relations avec une colonne 'Source' & une colonne 'Target' (avec des majuscules dès le départ, ça évite d'y revenir ensuite)
- il faut conserver un identifiant unique pour chaque tweet,( c'est déjà le cas dans la base de données ou le phirehose de twitter)
- il faut conserver la date pour pouvoir établir un graphe dynamique (au cas ou, la conserver ne prend pas énormément de place).
Je pars du principe, que le fichier original provient d'une extraction directe depuis une base de données telle celle que le framework 140dev écrit par Adam Green et disponible sur son site permet de construire aisément (je remercie en passant F. Clavert de m'avoir expliqué tout ça il y a quelques temps). Ce fichier comporte les colonnes suivantes au moins : numéro d'identification unique d'un tweet, date de création du tweet, nom de l'auteur, pseudonyme (@)
S'il faut les extraire d'une base php/mysql comme 140dev, avant l'export il s'agit de mettre le tableau en forme avec :
SELECT \`tweet_id\` , \`tweet_text\` , \`created_at\` , \`screen_name\` , \`name\` FROM \`tweets\`--> si vous utilisez l'interface de phpmyadmin, vous aurez probablement "WHERE 1" qui s'ajoutera, ainsi qu'une ligne du genre LIMIT : 0 to 30, ce n'est pas un problème
Open/gggle Refine accepte un grand nombre de formats de fichiers au départ, partons du principe que l'on travaille en .csv. Ne pas oublier de préciser le signe utilisé pour séparer les colonnes, si ce n'est pas déjà une virgule, (moi j'ulitise systématiquement le ; ) et l'encodage des caractères (car Refine, reprendra ces indications pour encoder le fichier final) Il est essentiel de ne pas cocher la case proposant une reconnaissance automatiquement de la nature des contenus des colonnes ("parse cells text into numbers, dates, etc."), sinon Refine va se mettre à arrondir les identifiants des tweets ou pire à les exprimer sous forme xxx e17.
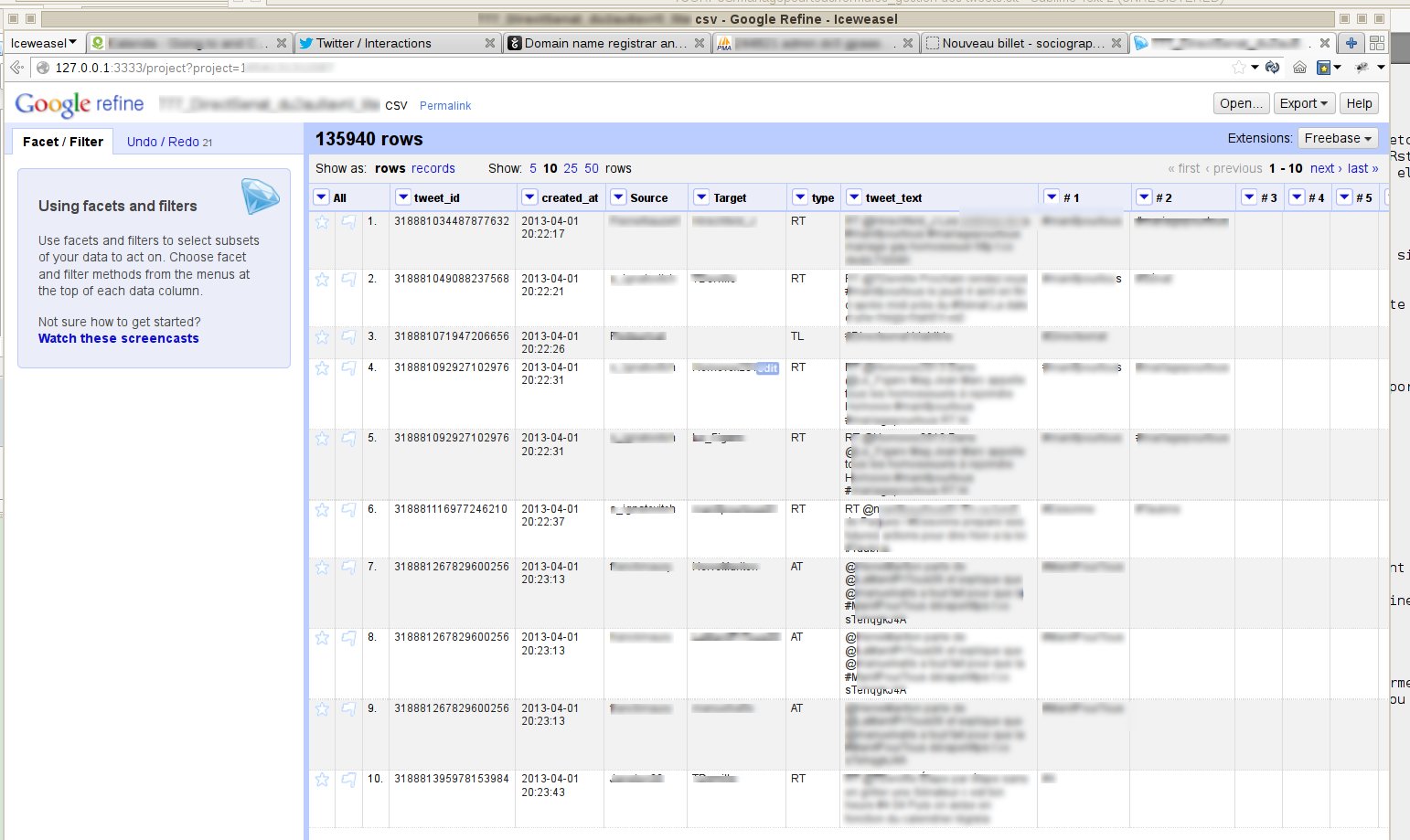
L'opération va consister à :
- isoler les informations permettant de générer un graphe correcte les auteurs de tweets et leurs destinataires
- produire des informations supplémentaires permettant de qualifier chacun des tweets. Ces informations permettront dans Gephi de tester la correspondance entre des caractéristiques de réseaux des noeuds ou des liens et des caractéristiques expressives ou documentaires des usages des tweets:
- le type de tweets (si c'est un RT, si c'est un tweet adressé à la TL, ou à quelqu'un en particulier, un @, etc.).
- les hashtags associées à chacun des tweets.
Extraction des mentions (@) et des hashtags(#)
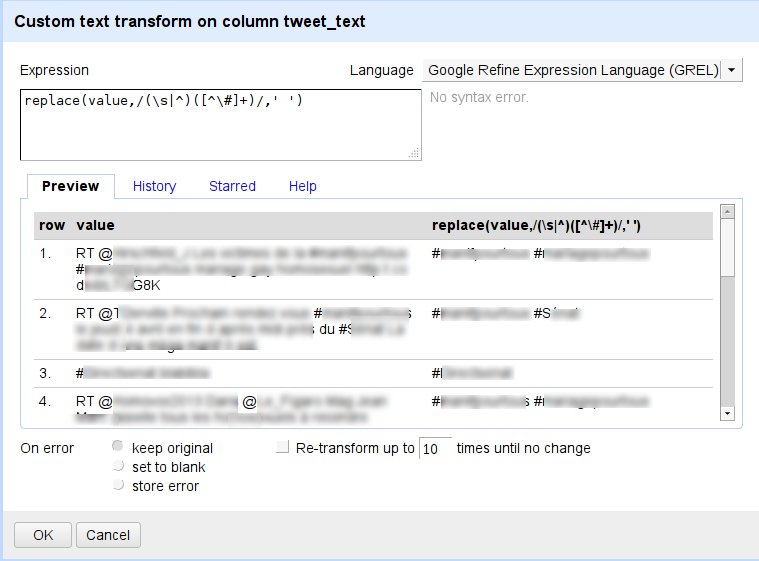
L'extraction des mentions et citations est simple, il suffit d'opérer les commande suivante sur la colonne des tweets.
Tout d'abord, il s'agit de nettoyer les signes de ponctuations qui 'collent' régulièrement aux mentions et aux hashtags :
--> sur la colonne des tweets, cliquer sur /edit column/add column based on this column/ avec l'opération suivante
replace(value,/\[\,\;\:\.\?\/\!\=\+\"\'\-\(\)\\[\\]\]/," ")--> cliquer sur /edit column/add column based on this column/ avec l'opération suivante
replace(value,/(\s|^)(\[^\@\]+)/,' ')On peut renommer cette colonne 'Target'. Dans la foulée, on recommence immédiatement l'opération (toujours à partir de la colonne des tweets) en créant une seconde colonne appelée '#' pour isoler cette-fois-ci les hashtags
--> cliquer sur /edit column/add column based on this column/ avec l'opération suivante
replace(value,/(\s|^)(\[^\#\]+)/,' ')On peut réordonner les colonnes pour avoir la colonne des 'screennames' en face de celle des mentions/'Target'
--> cliquer sur all/edit columns/reorder or remove columns
Passage d'une liste de tweets à une base de relations
Ensuite on doit passer en mode records pour pouvoir autonomiser chacune des différentes mentions au sein d'une relation unique et distincte des autres mention du même tweet d'origine tout en manipulant comme des ensembles uniques et cohérents les différentes lignes ainsi créées.
Sur la colonne 'Target':
--> cliquer sur edit cells/common transform/trim leading and ending spaces/ ainsi que sur 'collapses consecutive spaces'
--> puis cliquer sur edit columns/split into several columns. ici, on utilise l'espace comme caractère de séparation et on ne spécifie aucune valeur limite pour le nombre de colonnes (en général il y en a une dizaine maximum de créées pour la longueur très limitée d'un tweet)
À ce moment une opération terrifiante doit être menée jusqu'à son terme, c'est la transposition des cellules ordonnées dans différentes colonnes en cellules ordonnées dans différentes lignes. Alors que l'on vient de répartir l'ensemble des '@' de chaque tweets sur différentes colonnes, on va faire en sorte qu'ils restent au sein de la même entité que leur tweet d'origine, sans être inscrit pour autant sur la même ligne . En fait, on va les déplacer dans ce que l'on peut appeler des "sous-lignes", c'est-à-dire des lignes qui dépendent de leur ligne d'origine et ainsi former un 'record' contenant une ligne principale (avec le tweet d'origine) et des lignes différentes pour chacune des mentions/@ que comportait le tweet.
--> cliquer sur edit columns/transpose cells across columns into rows/ . On sélectionne la première et la dernière colonne des 'Target' (par ex. "Target1" et "Target9", on indique un nouveau nom de colonne pour (1column) : 'Target' de nouveau, par exemple, on coche ignore blank cells et fill down in other columns
Remarque importante : si d'aventure, on a oublié de cocher 'fill down', alors on ne lance surtout pas l'opération de 'fill down' seule ensuite : les lignes vides dans le cas où le tweet ne contiendrait véritablement aucun hashtag seraient malgré tout remplies par le hashtag de la ligne qui les précède... Donc si on a oublié de cocher la case 'fill down' dans la fenêtre,' un simple 'undo' fera l'affaire et permettra de recommencer la manipulation en entier.
À partir de là, on peut déjà se lancer dans Gephi, il suffit de changer le nom de la colonne 'screennames' en 'Source', d'enregistrer le tout en .csv, et c'est parti !
Séparer les hashtags
Sinon on peut prendre le temps de séparer les hashtags dans des colonnes différentes pour pouvoir plus tard les trier, et pour pouvoir les faire apparaître dans le graphe comme des caractéristiques des liens entre deux nœuds sur la colonne '#'.
--> cliquer sur edit cells/common transform/trim leading and ending spaces & collaspes consecutive spaces
--> cliquer sur edit columns/split into several columns. Là on utilise l'espace comme caractère de séparation et on ne spécifie aucune valeur limite pour le nombre de colonne (en général, il y a une bonne douzaine de colonnes créées). Pour le moment, je n'ai pas encore réfléchi à la manière de les ordonner dans l'ordre alphabétique ou autre... Il faut que je teste un peu l'usage dans Gephi, et j'updaterai le post bientôt (ou pas...).
Identifier les types de tweets
Ce qui est intéressant avec open refine, c'est qu'à ce niveau-là, il devient relativement aisé de qualifier les types de tweets à partir de leur syntaxe (NOTE: ces infos sont indicatives et il ne faut en aucun cas se fier uniquement et totalement à ce type de données par la suite - je développerai plus tard si besoin, mais, en somme, elles permettent d'évaluer grossièrement la nature du corpus, rien de plus...) . L'objectif ici consistera à distinguer dans une même colonne 'types', les retweets (RT), des tweets adressés à certaines personnes tels que les mentions @ (AT), des tweets adressés de façon générale aux followers d'une timeline (TL) (NOTE2 : il est probable que cette liste évolue, car, après discussion avec C. Prieur / @twytof, il manquerait le type des tweets avec mention ET url, j'updaterai ASAP)(ou pas...).
En reprenant la colonne des tweets :
--> clic sur facet /text filter (case sensitive), on indique 'RT' comme valeur
Il est possible que des erreurs se glissent (les caractères'PORTE' dans un tweet répondront positivement à ce filtre) mais la proportion n'est pas importante, surtout que nombre des RT sans mention sont des demandes de RT le plus souvent. Sinon il suffira d'écrire une regex plus précise [UPDATE : en régie, C. Prieur m'indique que sous unix/linux/etc., l'usage de <RT> évite la correspondance avec des caractères inclus dans un mot entier comme "PORTE", à tester sous Refine pour voir si ça marche aussi]
--> cliquer sur /edit column/add column based on this column. On l'appelle 'type' puis on tape 'RT' et on déselectionne le filtre de texte
sur la colonne 'Target' cette fois-ci :
--> cliquer sur facet/customized facet/facet by blanks/ . On inclut les 'true' pour n'afficher que les tweets qui ne comportent pas de mention
sur la colonne 'Types' :
--> cliquer sur facet/customized facet/facet by blanks/ . On inclut les 'true' pour n'afficher que les tweets qui ne sont pas déjà des RT ou des demandes de RT clic sur edit cells/transform... puis on tape 'TL' et on déselectionne le filtre de texte
enfin toujours sur la colonne 'Types' :
--> cliquer sur facet/customized facet/facet by blanks/ . On inclut les 'true' pour n'afficher que les tweets qui ne sont pas déjà des RT ou des demandes de RT ou des adresses aux TL uniquement
--> cliquer sur edit cells/transform . On tape 'TL' et on déselectionne le filtre de texte
Voilà, c'est déjà une bonne base pour explorer ensuite le graphe dans Gephi... Même si à ce stade les interprétations plausibles sont nombreuses (trop) et donc fragiles (très), il faudra alors se pencher sur la forme et les usages qui sont faits des tweets récoltés. Il faudra prendre en compte les singularités du corpus de tweets, qui peuvent pour le coup contrecarrer toute méthode de traitement des données bêtement appliquée sans une once de problématisation.
Il reste encore à exporter le fichier, tel qu'indiqué au milieu du post, et choisir un bon algorithme de visualisation, le Force Atlas 2 étant devenu une norme pour ce qui concerne la visualisation des tweets, ce qui n'est peut-être pas si évident que cela (Martin Grandjean propose de le cumuler avec fruchtermann-Rheingold sur des petits réseaux). En tout cas, voici, en dessous, la première visualisation (particulièrement touffue, #furball) dans Gephi d'un graphe de 20.000 nœuds et environ 80.000 liens pondérés, qui représente un corpus d'environ 120.000 tweets et 20.000 twitters (chacun des tout petits points bleus représente une personne qui twitte). Sur ce type de corpus, l'usage de l'algo OpenOrd peut être intéressant. Le travail ne fait donc que commencer, bien entendu...