Formatage des données TCAT pour iRamuteQ
Twitter autorise la récupération de corpus de tweets et de leurs metadonnées à partir de son API. Des solutions permettent d'effectuer cette collecte, TCAT par exemple, un projet de Digital Methods Initiative. IramuteQ est un logiciel qui permet des analyses lexicales suivant la méthode Reinert (le même genre que Alceste), particulièrement intéressantes dans des cas de controverses. Comment formater les données que l'on vient de récupérer avec DMI-TCAT sur l'API de Twitter afin d'en faire l'analyse dans iRamuteQ ?
Dans IramuteQ, il existe un bouton pour importer des données venant de TCAT. Mais je ne l'ai jamais utilisé, je n'en parlerai donc pas ici. Dans ce post, on va aborder une manière simple, rapide et adaptable (donc sûrement améliorable aussi) de s'atteler à cette tâche. Il suffit de disposer d'une installation fonctionnelle de R (qui est forcément déjà installé pour iRamuteQ) et des outils fournis par le Tidyverse.
Cette méthode est, bien entendu, garantie 100% opensource, elle fonctionne sous linux et macOS, et très probablement sous windows pour peu que Rstudio et iRamuteQ soit déjà installés. Comment va-t-on procéder ici ? On ne va pas travailler à partir d'un exemple, comme c'est souvent le cas dans les tutoriels. Je vais simplement commenter le code, qui pourra être recopié à peu près en l'état, chacun·e restant responsable de la façon dont iel l'adaptera à sa propre configuration. Il est possible de récupérer ce code soit dans un script R, à quelques adaptations près, soit dans un notebook ou un document Rmarkdown (.rmd) dans Rstudio (c'est sous cette forme, pas forcément la plus adéquate au départ, que je l'ai fourni la première fois à un masterant qui se lançait dans l'analyse d'une polémique sur Twitter, et tout a très bien marché).
DMI-TCAT, de son vrai nom Digital Methods Initiative Twitter Capture and Analysis Toolset, distribue les données et les métadonnées de chaque tweet dans une base PHP/mySQL qui permet l'export en .csv. Les données en sortie de l'API sont en JSON et dans un ordre spécifique, DMI-TCAT les réordonne selon d'autres critères, et calcule quelques variables supplémentaires. Aussi, la manière de formater les données pour iRamuteQ est probablement aisément adaptable depuis un autre type de récupération plus fidèle au format de sortie de l'API. Il suffira alors de changer le nom des colonnes et le principe de formatage devrait rester sensiblement le même.
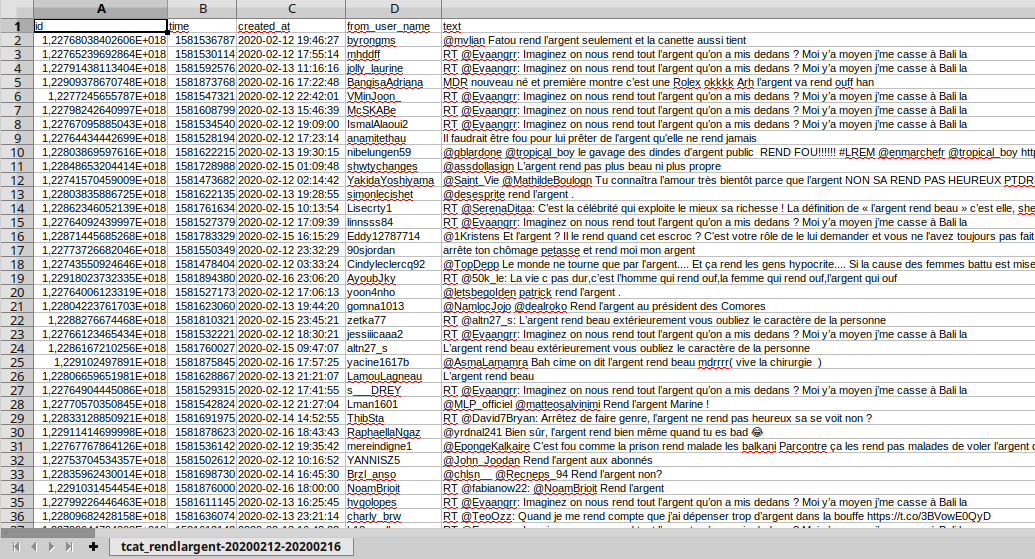
On part de ça (vu dans un tableur comme libreoffice calc) :
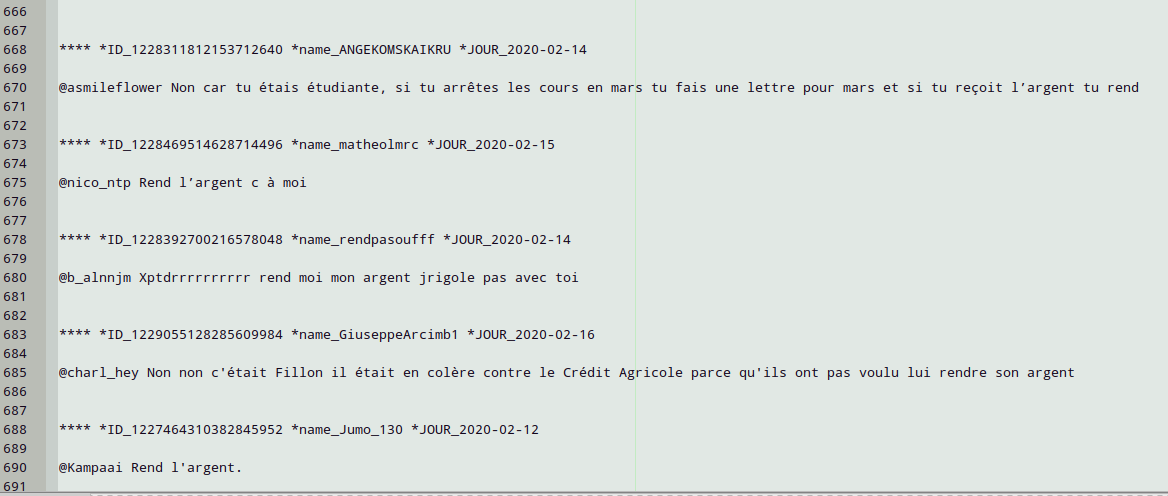
On veut arriver à ça (vu dans un éditeur de texte comme Geany) :
Principe général du formatage avec R
R fonctionne avec toute une série de paquets logiciels qui s'assemblent de façon modulaire et s'articulent plus ou moins simplement. Afin de simplifier les éventuels chevauchement de fonctions, les incompatibilités formelles (deux paquets pensés dans des contextes bien différents peuvent requérir des syntaxes contradictoires, etc.), ou les "trous" logiciels entre des paquets, une équipe autour de H. Wickham et Rstudio a patiemment construit le tidyverse, un ensemble de paquets qui tente de reconstruire une certaine cohérence dans le bazar. L'objectif consiste essentiellement à nettoyer/ranger [to tidy] (en gros à konmari-ser) le traitement des données à partir d'une syntaxe simple reposant sur des verbes permettant la production de variables dans des tableaux (des dataframes ou des tibbles). Dans ce post, on va donc filtrer, muter et transmuter, remplacer_des_chaînes_de_caractères, réunir et exporter.
En réalité, il n'est pas véritablement nécessaire d'en savoir plus et ce code est écrit pour permettre de n'avoir qu'à choisir les noms des bonnes colonnes sur lesquelles appliquer les bons verbes. Il faut tout de même comprendre un peu ce qu'est une REGEX, une expression régulière, et la façon dont elle permet de manipuler formellement des chaînes de caractères, alphabétiques, numériques, ponctuations, etc. Les REGEX permettent de les décrire, de les rechercher, de les manipuler en ajoutant, retranchant, réordonnant, recombinant ou extrayant ces chaînes de caractères. Quelles chaînes de caractères va-t-on traiter ici ? Essentiellement les contenus des colonnes de date, du nom des comptes twitter, des tweets eux-mêmes, etc. Pour se faire une idée des manières formelles de décrire tel type de caractères ou tel type de chaîne de caractère, on peut utiliser la cheatsheet de stringr (le paquet dédié aux manipulations de caînes de caractères dans le tidyverse) qui est particulière synthétique et limpide.
Pour utiliser ce script et réussir à formater ses données pour iRamuteQ, il peut toutefois amplement suffire de saisir le principe général des REGEX plutôt que de savoir les manipuler concrètement, dans la mesure où non seulement elles sont déjà écrites, mais en plus elles restent particulièrement simples (la joie de manipuler des REGEX est immense, s'en priver est absurde...). En effet, l'essentiel du script présenté ici consiste à sélectionner des colonnes, à en effacer certaines parce qu'elles seront inutiles à l'analyse iRamuteQ, à en conserver d'autres telles quelles, et à en transformer d'autres encore pour qu'elles deviennent des variables qualifiant les segments de textes que iRamuteQ traitera par la suite. Dans une dernière série d'opérations, on réunit ces colonnes pour n'en faire plus qu'une seule que l'on exporte dans un fichier txt. Et voilà !
Charger les paquets et importer le jeu de données
Pour commencer, il faut charger les paquets dont on aura besoin. je les détaille en-dessous, mais il est fort possible qu'un library(tidyverse) suffise pour remplacer cette liste...
library(tibble)
library(tidyr)
library(dplyr)
library(stringr)
library(lubridate)
library(ggplot2)
library(tibble)
library(forcats)
library(readr)
library(knitr)
Twitter fournit pour chaque tweet un identifiant unique qui doit faire pas loin de 20 chiffres de long, et se voit régulièrement représenté par les tableurs et par R sous la forme scientifique, rendant illisible la totalité de l'identifiant. Aussi, en cas de problème d'affichage des colonnes id ou tweet_id, il faut désactiver l'affichage de la notation scientifique. Et si l'on désire ensuite la rétablir, il suffira de redescendre la valeur 99 à un nombre inférieur de digits après lequel la notation sera utilisée.
# désactivation de la notation scientifique sur les identifiants des tweets
options(scipen=99)
Ensuite, il s'agit de charger le fichier que l'on aura pris soin d'exporter depuis DMI-TCAT et d'enregistrer sur son disque dur (on travaille en principe toujours sur une copie, afin de ne pas avoir à télécharger une seconde fois les donnés en cas d'erreur et de destruction du premier jeu de données). Les arguments passés dans la fonction read.csv2() permettent de spécifier le séparateur de colonnes utilisé par votre fichier, pour TCAT c'est la virgule, et d'indiquer que toutes les colonnes de texte resteront bel et bien des chaînes de caractères au lieu d'être transformées en variables catégorielles, c'est-à-dire en factors1.
# IMPORTER la base de tweets en indiquant le chemin où se trouve le fichier csv produit par tCAT
tw_base <- read.csv2("/dossier_dans_lequel_sont_stockées_les_données/tcat_rendlargent.csv", stringsAsFactors = F, sep = ",")
# SI L'ON COMPTE UTILISER DES DATASETS COMPLÉMENTAIRES DE TCAT, ON PEUT D'ORES ET DÉJÀ LES CHARGER ICI, en dupliquant cette ligne et en l'assignant à un nouvel objet R
tw_hashtags <- read.csv2("/dossier_dans_lequel_sont_stockées_les_données/tcat_rendlargent_hashtags.csv", stringsAsFactors = F, sep = ",")
À partir de là, on est prêt·e à se lancer dans le formatage du jeu de données importé depuis TCAT.
Simplification du dataset avant formatage
Selon la taille du jeu de données récupéré dans TCAT, suivant en fait la quantité de tweets, donc de lignes, que celui-ci contient, et suivant la quantité de RAM de l'ordinateur que l'on utilise, il peut être intéressant de ne conserver qu'un minimum de colonnes, surtout que Twitter, puis TCAT, en fournit de nombreuses qui ne vont jamais servir à une analyse iRamuteQ. Dans cette portion de code, on trouve une liste des colonnes qui seront retirées ou ajoutées du jeu de données selon que la ligne qui les nomme commence par un # ou pas. Cette opération de sélection et de déselection de certaines lignes en les faisant commencer par un # s'appelle décommenter/commenter, et elle consiste généralement à indiquer à R de ne pas prendre en compte les lignes du scripts qui sont précédées d'un #. Il faut aussi bien penser à toujours marquer les noms des colonnes entre guillemets et à les faire suivre d'une virgule à chaque ligne.
Le plus souvent, une analyse iRamuteQ s'appuiera sur les variables de temps created_at, sur le nom/handle de chaque abonné·e from_user_name, sur le contenu des tweets text, la langue des tweets lang, et quelques autres encore. D'autres variables ne sont pas fournies toutes prêtes par TCAT et devront être construites en cours de route, mais nous verrons cela un peu plus loin.
Un exemple intermédiaire d'adaptation d'une variable de TCAT à l'analyse iramuteq, est celui de l'extraction d'une variable d'années, de mois, de jours, ou d'heures de la variable de date unique created_at que propose TCAT. En effet, suivant les corpus, on n'aura besoin d'une précision plus ou moins grande dans iramuteq pour qualifier les tweets. Dans notre version du script, les variables annee et mois restent commentées d'un # et ne seront donc pas passées lors de l'execution du script.
# on supprime les colonnes inutiles à l'analyse
tw_base <- tw_base %>%
select(c(
# commenter ou DÉcommenter (ajouter ou enlever les # en début de ligne) les noms des colonnes à la liste suivante pour qu'elles soient CONSERVÉES dans le jeu de données à formater
"id",
# "time",
"created_at",
"from_user_name",
"text",
# "filter_level",
# "possibly_sensitive",
# "withheld_copyright",
# "withheld_scope",
# "truncated",
"retweet_count",
"favorite_count",
"lang",
"to_user_name",
# "in_reply_to_status_id",
# "quoted_status_id",
# "source",
# "location",
# "lat",
# "lng",
# "from_user_id",
# "from_user_realname",
# "from_user_verified",
# "from_user_description",
# "from_user_url",
# "from_user_profile_image_url",
# "from_user_utcoffset",
# "from_user_timezone",
# "from_user_lang",
# "from_user_tweetcount",
# "from_user_followercount",
# "from_user_friendcount",
# "from_user_favourites_count",
# "from_user_listed",
# "from_user_withheld_scope",
# "from_user_created_at"
)
) %>%
# on arrondit la date/heure de created_at à l'heure "pile" antérieure et on génère 2 nouvelles colonnes jour et heure plus facile à transformer en variables pour iramuteq :
mutate(
created_at = as.POSIXct(tw_base$created_at),
# annee = floor_date(created_at, "year"),
# mois = floor_date(created_at, "month"),
jour = floor_date(created_at, "day"),
heure = floor_date(created_at, "hour")
)
Ensuite, par sécurité, j'ai inséré une commande qui débarasse le texte des tweets des caractères suceptibles de compliquer l'usage des regex par la suite. Cette étape est probablement dispensable dans la mesure où iRamuteQ permet de nettoyer certains caractères de lui-même. Il est donc possible d'effacer cette première commande du bloc de code ou de la commenter elle aussi.
Enfin, une dernière commande permet d'extraire les retweets du corpus qui sera traité par iRamuteQ. Concernant l'analyse des RT dans iRamuteQ, il existe différentes écoles, pas vraiment antagonistes d'ailleurs. En fait, tout dépend de la manière dont le corpus a été collecté et de ce que l'on y cherche : s'il n'est constitué que d'un seul hashtag, évacuer les RT est tout à fait approprié et offre l'occasion de se concentrer sur les discours des seuls tweets originaux, sans subir l'influence des RT qui feraient pencher l'analyse iRamuteQ en sur-représentant le vocabulaire des seuls tweets retweetés.
Cependant, si l'on analyse une controverse qui se déploie sur différents hashtags, avec des stratégies d'indexation variables en quantité de RT mais surtout différentes de la part de différents groupes d'abonné·es, inclure les RT dans l'analyse d'iRamuteQ peut prendre du sens, à condition toutefois, de construire, nous allons y venir, une variable supplémentaire marquant la nature du tweet, original ou RT, afin que iRamuteQ puissent indiquer si certaines classes lexicales sont particulièrement affectées par les stratégies de RT ou pas.
# nettoyage des caractères pénibles avec l'analyse automatisée et les REGEX
tw_base <- tw_base %>% mutate(
text = str_replace_all(text, "\\$|\\*|\\-", " "),
from_user_realname = str_replace_all(from_user_realname, "\\$|\\*|\\-", " ")
# dupliquer cette ligne pour nettoyer d'autres variables issues de textes rédigés par les abonné·es en remplaçant from_user_realname, les deux fois, par le nom de la nouvelle colonne à nettoyer (ne pas oublier d'ajouter une virgule en fin de ligne alors).
)
# sélection des seuls tweets originaux et abandon des RT. Commenter la ligne si l'on désire conserver les RT
tw_base <- tw_base %>% filter(str_detect(tw_base$text, "^RT @\\w+", negate = TRUE))
Création de nouvelles variables
La création de variables supplémentaire peut vraiment prendre des formes particulièrement distinctes. On en recense tout de même trois formes principales :
- l'adaptation d'une variable fournie par TCAT dans le jeu de données principal ou bien dans les jeux de données parallèles qu'il est assez facile de recombiner au premier (en opérant des jointures par exemple...). Ce type d'adaptation peut aussi, autre exemple, consister à créer une variable catégorielle des types d'abonné·es à partir de leur nombre de followers (from_user_followercount), etc.
- le recodage manuel qui nécessite la qualification de chaque ligne à partir d'une interprétation que l'on doit effectuer (par exemple le codage des types d'images ou de textes utilisés sur les profils par les abonné·es, etc.). Le recodage manuel implique souvent de faire une sortie du fichier pour le recoder dans un tableur ou dans openrefine, le plus souvent, puis de le réimporter par la suite dans R. on utilisera alors les fonctions
write.csv2pour l'export etread.csv2pour l'import, comme indiqué en début et fin de script. - le croisement avec d'autres types de données, des dictionnaires par exemple, notamment pour déterminer une liste spécifique de "stop words"... Là, les possibles sont tellement vastes, qu'on ne s'étendra pas sur la question.
# il n'est pas nécessaire de donner des exemples ici
# on pourra éventuellement voir cela dans un second post
Formatage des variables pour iRamuteQ
iRamuteQ permet d'analyser des corpus de textes en marquant chaque texte ou portion de texte avec des variables. Si on analyse une œuvre littéraire, par exemple, on pourra attribuer à chaque ouvrage composant le corpus une variable indiquant sa date d'édition, une autre son éditeur, etc. Pour un corpus d'entretiens sociologiques, on pourra indiquer des variables sur les données socio-démographiques concernant la personne interviewée, etc.
Je ne vais pas développer ici tous les détails du formatage (ils sont repérables dans le code, de toute façon), la documentation de iRamuteQ est super bien faite, il suffit de la récupérer sur le site web du logiciel, et plus spécifiquement la page concernant le formatage du texte dont on va suivre les règles ici.
Pour que ces variables soient distinctes du texte même à analyser, iRamuteQ marque les variables d'un signe distinctif, en l'occurence une "*", et en associant la modalité adéquate à sa variable à l'aide d'un "_", ce qui donne la chaîne suivante : '*variable_modalité'. La première des variables, quelle qu'elle soit, doit être construite un peu différement des suivantes : en plus de l'étoile la désignant comme variable, elle doit être aussi précédée de 4 étoiles, qui marquent le début de chaque bloc texte + variables.
Notons en passant qu'il n'est pas forcément conseillé de coder l'identifiant unique comme première variable, comme je l'ai fait dans l'exemple ici. En fait, tout dépend de la taille du corpus, parfois un identifiant plus cours peut être généré comme nouvelle variable (à l'étape précédente), parfois, il n'est pas nécessaire d'avoir des identifiants uniques.
# on formate les variables :
tw_formated <- tw_base %>%
# on génère le nom des variables qui précédera chacune des modalités qualifiant un texte du corpus :
mutate(
# on introduit la ligne des variables avec les **** précédant la 1ère variable (ici l'identifiant unique des tweets)
id = str_replace(id, "^", "\\*\\*\\*\\* \\*ID_"),
# ensuite, on construit les variables en remplaçant le début (désigné par le circonflexe) de chaîne de caractère par un nom de variable
jour = str_replace(jour, "^", "\\*JOUR_"),
# dupliquer cette ligne autant de fois qu'il y a de variables pour qualifier les textes du corpus : en remplaçant les 2 occurrences de "jour" par celles du nom de la variable dans TCAT, et en remplaçant JOUR par le nom de la variable qui servira dans iramuteq. par exemple :
from_user_name = str_replace(from_user_name, "^", "\\*NAME_"),
# formatage du texte lui-même, et il y a deux manières de l'aborder :
# soit comme un bloc unique auquel on ajoute en début de chaîne de caractère un retour à la ligne pour le distinguer visuellement des variables qui le caractérisent (mais le logiciel s'en moque probablement...)
text = str_replace(text, "^", "\\\n")
# soit comme un bloc traversé de thématiques (des portions de textes) (et, dans ce cas, il faut commenter la ligne précédente et décommenter les 3 lignes suivantes...)(OUI, MÊME LA LIGNE AVEC LA VIRGULE !). Par défaut, ce script servant à formater des tweets, c'est le formatage du texte comme bloc qui est choisi
# ,
# text = str_replace(text, "^","\\-\\*thematique_TITLE \\\n"), # TITLE est un exemple de titre, il faut donc bien évidemment l'adapter
# Summary = str_replace(Summary, "^","\\-\\*thematique_SUMMARY \\\n") # summary est un exemple à adapter aussi, on doit ajouter autant de lignes de ce type qu'il y aura de thématiques, c'est-à-dire de types de textes composant le corpus à analyser
)
Réunion des colonnes et export du texte formaté
Cette dernière étape consiste à sélectionner et ordonner les seules colonnes jusqu'ici bien distinctes, et puis les réunir en une seule, qui deviendra un texte en lui-même une fois exporté. À partir de cette portion du code, l'ordre indiqué des variables sera définitif. Chose importante à noter, il faut garder la colonne text contenant le texte final en toute dernière position de cette sélection...
La réunification se fait petit à petit : on réunit d'abord toutes les colonnes qui serviront de variables pour iRamuteQ ensemble, éventuellement on réunit les colonnes des thématiques entre elles, et enfin, seulement, on réunit variables et texte/thématiques en une seule colonne finale. Afin de rendre l'ensemble plus facile à lire à l'œil nu, on insère des sauts de lignes par-ci par-là.
# on sélectionne et ordonne les seules variables utiles à iRamuteQ :
tw_formated <- tw_formated %>%
select(id, from_user_name, jour, text) %>%
# bien entendu, on peut ajouter autant de variables que nécessaire, il suffit de les inscrire dans les parenthèses, séparés de virgules.
# on regroupe les différentes colonnes pour former les sections des variables :
unite(1:3,
col = "va",
sep = " ",
remove = TRUE) %>% # on assemble les variables sur une seule ligne, l'expression 1:3 doit voir le '3' remplacé par le nombre des variables qui figureront dans iramuteq, c'est-à-dire le nombre des noms de colonnes listés dans select() quelques lignes plus haut, moins 1 (car `text` ne sera plus considéré comme une variable par iramuteq).
# unite(2:3, col = "th", sep = "\\\n", remove = TRUE) %>% # si l'on a choisi de thématiser le texte il faut réunir les thématiques ensemble, et bien entendu adapter l'expression 2:3 au nombre 2:x avec x == nombre de thématiques.
# enfin on regroupe variables et texte/thématiques
unite(1:2,
col = "vath",
sep = "\\\n",
remove = TRUE) %>% # ici l'expression 1:2 reste constante, puisque toutes les variables et le texte( ou toutes les thématiques) ont déjà été regroupé en seulement deux catégories...
mutate(vath = str_replace(vath, "^", "\\\n\\\n"),
vath = str_replace_all(vath, "\\\\", "")) # ça n'est pas très élégant, mais il reste apparemment des \ incontrôlables...
Il ne reste plus qu'à exporter cette colonne complète et unique, et contrairement à l'habitude, on ne l'exporte pas en .csv mais en .txt et on pense à changer le nom du fichier, sinon toutes les analyses s'appelleront "rendlargent", ce qui serait facheux.
# export du fichier txt formaté pour iRamuteQ (ce n'est PAS un csv !!)
write.table(tw_formated, file="/dossier_dans_lequel_sont_stockées_les_données/Rendlargent.txt", quote = FALSE, sep = "", row.names = FALSE, col.names = FALSE)
Voilà, en principe, ce script est suffisant au moins pour commencer à explorer un corpus de tweets à l'aide de iramuteq, voir les principales classes lexicales et en tirer quelques pistes pour organiser l'analyse ultérieure.
-
la factorisation est un moyen d'économiser des caractères lors de l'écriture de chacune des observations d'une variable catégorielle : on remplace chacune des modalités par un chiffre, ainsi si la variable comprend 10 modalités différentes, chacune ligne contiendra seulement un chiffre de 0 à 9, au lieu qu'elle ne contienne la chaine de caractère alphanumériques entière du nom de chaque modalités. cf. McNamara A, Horton NJ. 2017. Wrangling categorical data in R. PeerJ Preprints 5:e3163v2 https://doi.org/10.7287/peerj.preprints.3163v2. ↩