Écrire du code et linéariser le récit scientifique
L'année dernière (non, en fait, le temps que je termine, c'était il y a 2ans ^^ ) dans un post consacré aux puzzles j'ai tenté de raconter combien la pratique des dits puzzles m'avait aidé à construire un plan de thèse. Ces puzzles demandent d'ordonner des éléments petit à petit, et de cerner l'ensemble d'un processus de linéarisation pour aboutir. Tantôt il n'y a pas d'ordre linéaire a priori, mais des règles d'ordonnancement spécifiques dont la linéarisation est à la fois une conséquence et une finalité ; tantôt il y a un ordre linéaire sous-jacent à découvrir, et c'est d'en faire l'hypothèse qui permet d'avancer jusqu'à la résolution du puzzle. À force de pratiquer ces petits puzzles, j'ai fini par transposer leurs règles dans la construction du plan puis dans la rédaction du texte de ma thèse. Cette transposition m'a finalement permit de réussir là où j'avais jusqu'ici échoué malgré les tonnes de conseils bien plus élaborés qu'on m'avait généreusement prodigués.
Dans ce post, j'aimerais réfléchir à un second ensemble de pratiques qui a joué un rôle important pour moi dans l'intégration des processus de linéarisation propres au travail d'enquête et à la production d'un discours scientifique. Ce second ensemble de pratiques s'est développé à peu près en parallèle de l'usage des puzzles. La linéarisation repose cette fois-ci sur l'écriture du code informatique, d'abord pour linéariser le traitement des données en SHS (sur ce point, c'est assez évident), mais aussi, en conséquences, pour linéariser le raisonnement qui en supporte l'analyse et, surtout, la présentation finale de celle-ci. L'impression que j'ai, c'est que le code n'est pas le fait d'un esprit naturellement ordonné et apte a priori à produire un séquençage linéaire des choses (#U+1F417). Au contraire, l'écriture du code intervient en amont, comme un exosquelette, les exigences intrinsèques de sa pratique contribuant à structurer le travail de raisonnement et d'écriture.
Il me semble que la linéarité du discours scientifique peut être un défi à trois niveaux : le raisonnement (pas nécessaire), le traitement des données (pas uniquement propre au quanti, mais souvent invisibilisé dans le récit des études quali), et enfin, la présentation/publication, ie. le récit du raisonnement. J'ai abandonné ma première thèse parce que je n'arrivais pas à rédiger un manuscrit satisfaisant. On m'a dit que j'étais perfectionniste, que je voulais trop en faire, que je ne savais pas ce que je voulais (ie. que je n'avais pas de stratégie de carrière), bref, beaucoup de choses contradictoires et finalement peu pertinentes pour décrire le problème. En fait, il n'était pas du tout question de perfection à accomplir, mais plus modestement de parvenir à privilégier un ordre et à produire de la linéarité face à un ensemble très important de notes, d'observations et d'interrogations accumulées au fur-et-à-mesure d'années de terrain.
Je pouvais exprimer les éléments de fond, théoriques ou méthodologiques, individuellement mais je perdais alors une grande partie du socle empirique de mon étude qui lui aurait donné, en principe, sa cohérence. Si, au contraire, je choisissais un "fil rouge" (cette façon banalisée de parler de linéarité sans jamais en fournir les mécanismes) narratif ou démonstratif, tout prenait paradoxalement une importance équivalente et rendait difficile le fait de tenir le cap de ce fil rouge. Par exemple, si je réussissais à stabiliser un ordre autour d'une thématique (après une longue discussion avec ma directrice, par exemple), alors des milliers de détails lié à ce thème précis surgissaient, tels une meute de popples teigneux. La multiplicité de leurs possibles combinaisons venait directement saccager le travail d'ordonnancement préalable des couches théoriques ou méthodologiques. À la fin, il finissait toujours par me manquer le problème central articulant terrain, méthode et théorie parce que chacun des trois ensembles débordaient de toutes parts.
Cette expérience fut particulièrement douloureuse du fait que l'analyse et les données empiriques ne s'articulaient jamais bien dans un texte final alors même que je pouvais en discuter pendant des heures, dès lors qu'une ou deux personnes étaient susceptibles d'orienter mon exposé par leurs questions (adapter mon discours à ces personnes justifiait de choisir tel élément plutôt qu'un autre). J'ai d'abord décidé d'abandonner ce premier travail de thèse, avant de le reprendre quelques années plus tard, mais sous un angle bien différent : il était clair que je n'avais aucune aisance pour produire un discours linéaire. Je savais par ailleurs très bien conseiller mes collègues pour consolider la rigueur du raisonnement de leurs propres textes. C'est comme lorsque je dois évaluer des articles pour des revues : je ne panique jamais face à l'ampleur de la confusion ou des difficultés que présentent les travaux à évaluer, et le peu d'éléments qu'un article ou un chapitre d'ouvrage soumettent à mon évaluation m'apparaissent toujours parfaitement appréhendables comparé à la quantité de détails que je n'arrivais pas à traiter dans mon propre travail.
En me réengageant dans un travail d'écriture aussi monumental que celui d'une thèse, je savais qu'il me faudrait externaliser et déléguer la production de discours linéaire. J'avais plusieurs intuitions : il ne faudrait jamais que je travaille seul, tout en étant le plus autonome possible sur l'approche de mon terrain, il me faudrait produire de nombreux rendus intermédiaires, bien plus que ce qui est possible de faire lorsqu'on est un·e doctorant·e dans un labo, qu'il me faudrait co-écrire, co-présenter, etc., et enfin, qu'il me faudrait un moyen que le texte se structure puis se produise comme "malgré moi". Seulement, le rôle potentiel du code n'était pas encore bien clair à ce moment-là, en fait, parce que, à 'l'époque, je ne codais rien du tout.
Comment le code est devenu un moyen d'externaliser la linéarisation de mon propos, à la fois comme outil concret de linéarisation et comme métaphore offrant des manières transposables à d'autres formes d'écriture ? Pour le comprendre, il faut repartir 10ans plus tôt, et comprendre la place de l'informatique dans mon parcours, de linux, des logiciels libres, de l'usage du terminal, des oneliners de awk et sed, des regex, du textmining, du nettoyage et du formatage des données avec openrefine, et, enfin, des questionnaires en socio et de l'usage de R et Rstudio. Pas de panique, il n'est pas nécessaire de comprendre ce que ces noms désignent, justement, je ne le savais pas non plus moi-même en les découvrant... Ce que je voudrais raconter, c'est comment le fait de les découvrir a transformé ma manière d'écrire.
En quête de linéarité : l'entrée du code dans le travail
Comment suis-je venu à écrire parfois un peu de code ? À la fois inévitable et complètement fortuit, voici une chronologie très synthétique (LOL) :
- j'utilise des systèmes linux depuis bientôt 20ans, parce que, étudiant, je n'avais pas d'argent à dépenser dans des systèmes qui servent principalement à faire acheter d'autres logiciels ensuite, et parce que, désormais, c'est le seul système qui ne subisse pas d'obsolescence programmée, et sur lequel les outils scientifiques sont de qualité ET gratuits. Ce qui me permet, suivant les années, de réaliser des enquêtes avec des budgets très serrés. En somme, sans Debian et les outils FOSS, j'aurais probablement abandonné la recherche en 2004... En 2008... Et aussi en 2013, comme en 2017... Et puis encore en 2020, bien entendu. Bienvenu·es dans la science en freelance ! Comme MacOS ou windows, on peut utiliser un système linux avec l'interface du "bureau" ou bien avec l'interface "textuelle" d'un terminal, avec les fameuses commandes et l'écran tout noir (cf. illustration). Dans les distributions linux, cette dualité est relativement explicite (alors qu'elle est masquée aux usagèr·es dans les autres OS) et dédramatisée. Elle n'en devient pas pour autant immédiatement accessible, néanmoins, il suffit de s'y intéresser pour découvrir que les commandes au premier abord plutôt austères sont en fait bien cool.
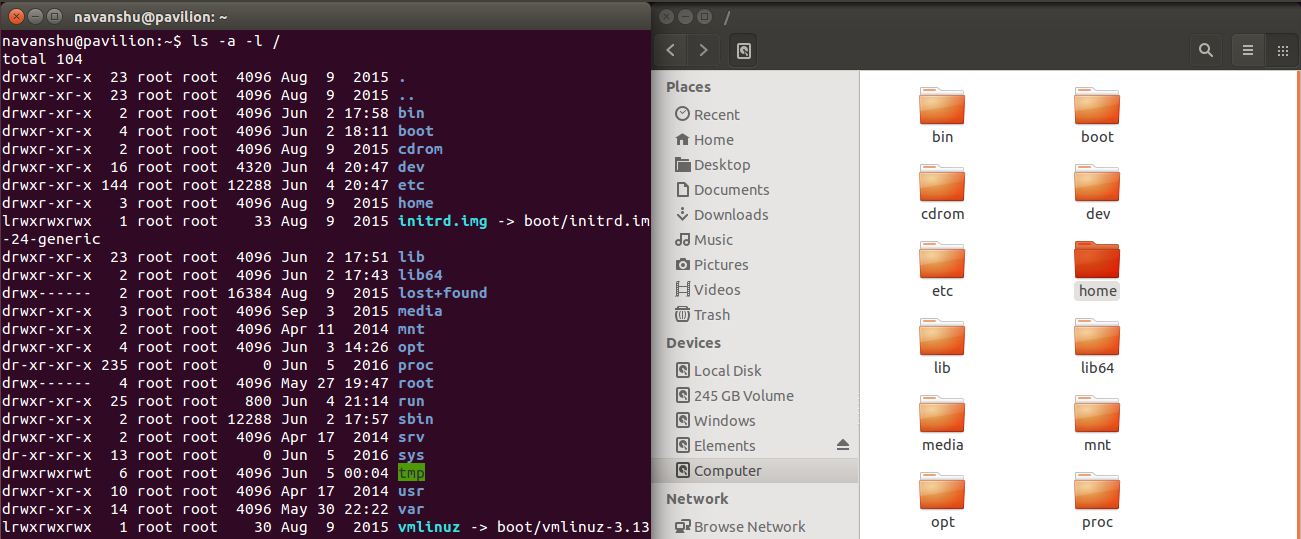
Dans cette image issue du site https://fossbytes.com/linux-lexicon-introduction-linux-shell-terminal/ on voit la représentation du navigateur de fichier, en ligne de commande à gauche et avec une interface graphique classique à droite
-
au début des années 2010, j'ai travaillé pour un projet ANR combinant avec allégresse approches "quali" et "quanti", et faisait voisiner un questionnaire en ligne avec des générateurs de noms, de l'analyse de réseaux, des interviews, de l'analyse lexicométrique, ainsi que de la modélisation multi-agent. Mon cerveau a explosé face à cette variété, mais ça me parlait et me plaisait au plus haut point. Bon, par contre, je n'y connaissais rien. Entre autres tâches, je me suis vu confier l'édition de tableaux qui listaient les relations que des sites web entretenaient entre eux : un site dans une colonne affichant un lien vers un autre site qui se trouvait alors dans une seconde colonne. Il fallait parfois opérer des transformations et des corrections dans ces données, et les formater... Si les tableaux étaient suffisamment petits, les opérations étaient possibles avec des tableurs traditionnels du genre de libreOffice Calc ou de Microsoft Excel. Mais lorsque le nombre de sites web listés est devenu plus important, puis que certaines opérations ont du n'être appliquées que dans certaines conditions très précises au sein des colonnes, le tout est devenu assez pénible à réaliser.
-
Pour remplacer l'usage du tableur, j'ai d'abord utilisé les outils de rechercher/remplacer d'un éditeur de texte, et cela m'a amené à découvrir les expressions régulières et la possibilité de manipuler des chaînes de caractères de manière formelle. Il n'était plus nécessaire de travailler dans l'espace d'affichage des données alphanumériques, dans le tableau lui-même, mais de "corriger" en amont dans un éditeur qui ne représentait pas le tableau comme un tableau, mais seulement comme un ensemble de lignes. Je pouvais corriger ou transformer le contenu des deux colonnes de sites web, simplement en appliquant des "rechercher/remplacer" qui ciblaient certaines lignes et pas d'autres (cf. illustration). C'était magique. Et cette manière permettait de séparer les choses à l'écran, avoir une liste d'expressions régulières dans un fichier à part, que je recopiais et adaptais pour appliquer une nouvelle transformation sur les colonnes. J'étais en train de découvrir les rudiments du nettoyage et du formatage de données.
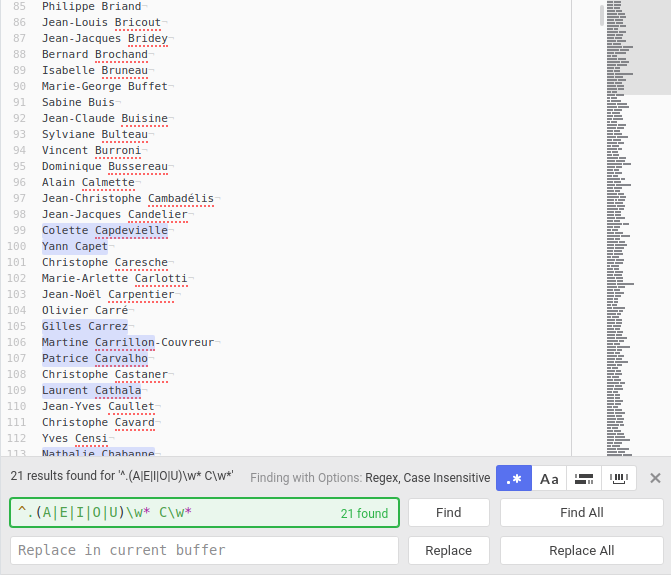
Recherche avec expression régulière des député·es dont la 2ème lettre du prénom est une voyelle et dont l'initiale du nom est un "C"
- Un collègue m'a alors pointé le logiciel OpenRefine, qui justement se donnait l'impérieuse mission d'aider à raffiner les données. Ce logiciel avait une interface WYSIWYG, avec une représentation du tableau de données équivalente visuellement (seulement) aux tableurs (cf. illustration). En plus de cette interface relativement standard, il offrait deux fonctions merveilleuses : d'abord il permettait de visualiser le résultat des expressions régulières avant de les appliquer véritablement (cf. illustration), et ensuite, toutes les opérations qui avaient été effectuées "à la main" étaient visualisables sous forme de code dans un autre onglet : on pouvait donc recopier d'un simple CTRL+C les dizaines d'opérations que l'on venait d'effectuer dans les heures précédentes. En fait, OpenRefine rendait automatiquement accessible le script des opérations déjà effectuées à la main (cf.illustration).
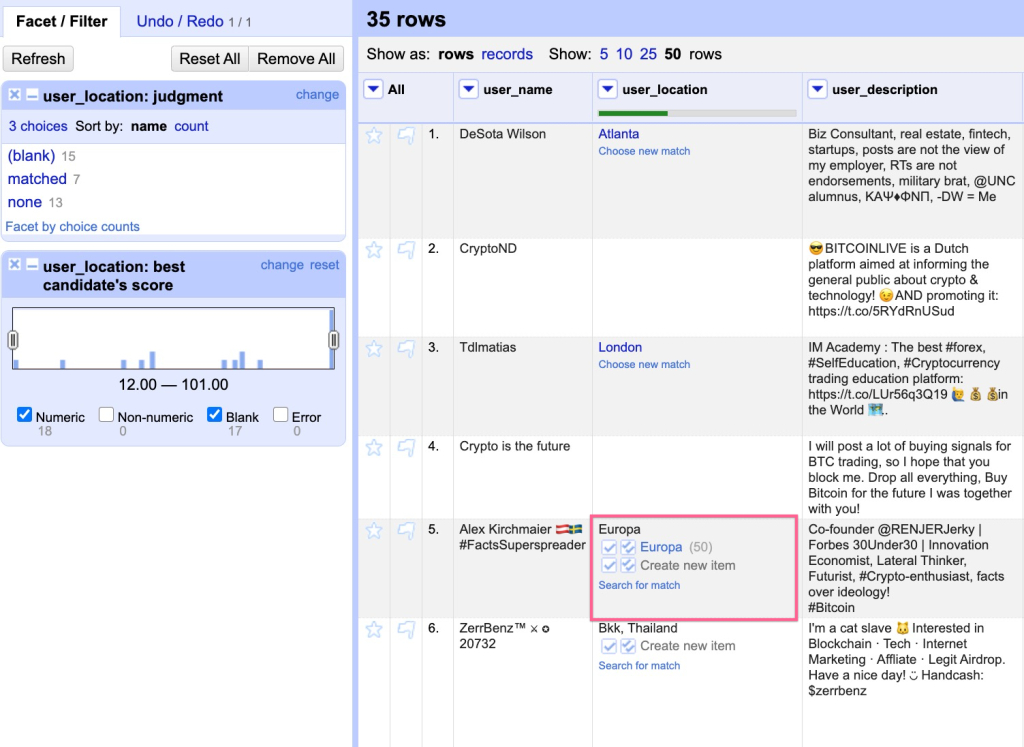
module tabulaire de OpenRefine, image provenant de ce post à thekeycuts.com
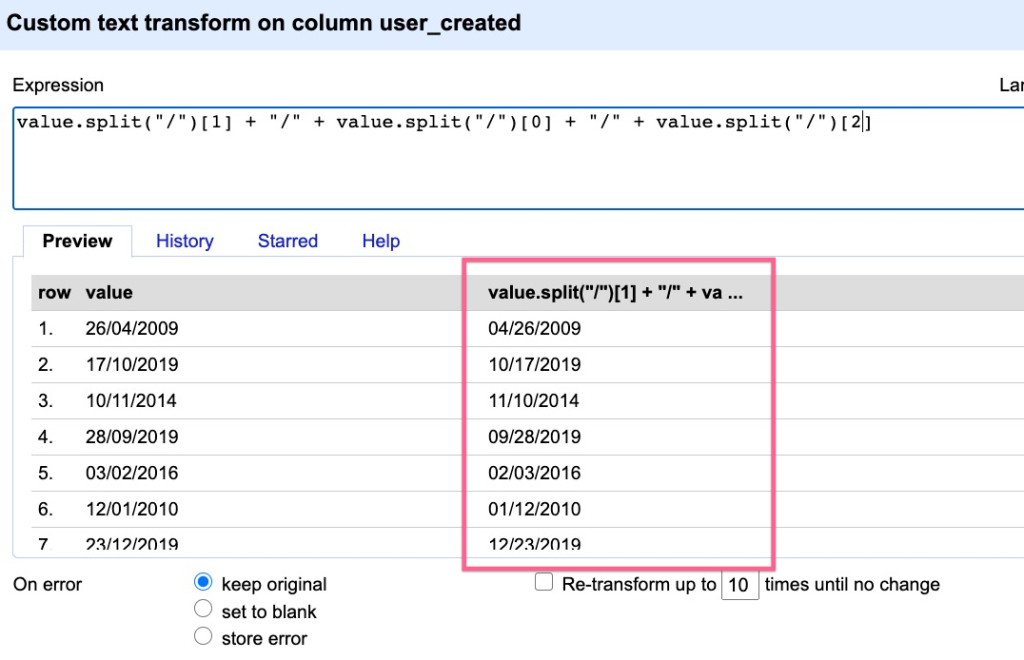
module d'expressions régulières de OpenRefine, ici pour le reformatage des dates
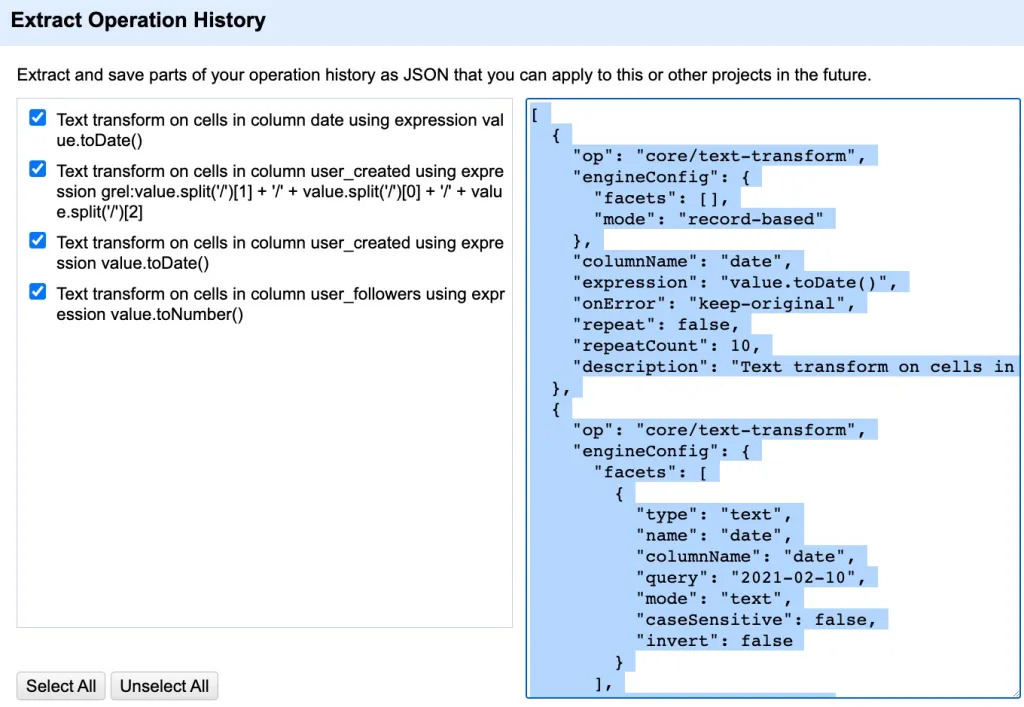
module dédié au script de OpenRefine, il rassemble la totalité des opérations effectuées
- Openrefine tournant grâce à javascript dans un navigateur web, son usage est rapidement devenu problématique lorsque j'ai travaillé sur des corpus assez lourds de tweets : d'un coup, OpenRefine, même sur une machine pas trop nulle (un macmini de base, au bureau), se mettait à turbiner pendant mille ans avant de donner un résultat. Je me suis alors tourné vers les outils du terminal du macmini, qui s'avèrent être les mêmes que ceux d'un système linux / debian, à savoir les commandes
grep,sed,gsub, et surtoutawk. Awk est une sorte d'outil de manipulation de données tabulaires en ligne de commande, c'est-à-dire qu'il permet de manipuler des tableaux dans un environnement qui ne représente pas les tableaux. Honnêtement, c'est une invention merveilleuse, seulement elle m'a fait souffrir le martyr, et il ne faut surtout pas commencer l'écriture de scripts par awk. Vraiment pas. Ceci étant dit, un environnement en ligne de commande me permettait de travailler sur des machines de piètre qualité (une sorte d'ancêtre du raspberry Pi) en traitant des corpus plus gros que ne l'autorisaient de bons ordis avec des logiciels WYSIWYG.
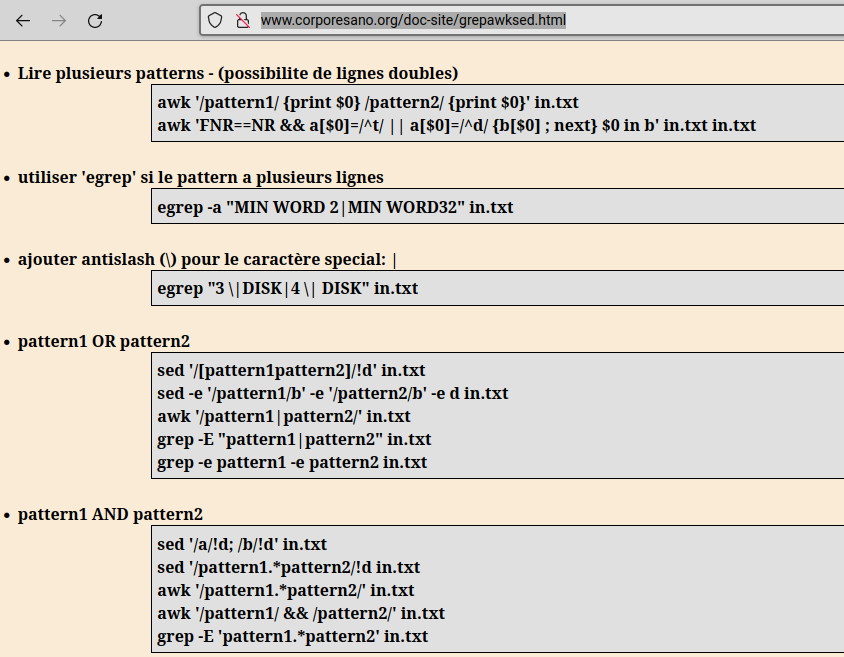
manipulation de données tabulaires avec awk, capture provenant de l'illustre corporesano.org
-
Openrefine permettait de "lire" les opérations effectuées à la main dans le tableau, sed et awk demandaient de construire une petite suite d'opérations avant d' exécuter le même genre d'opération sans jamais voir le tableau. Le code de openrefine permet de comprendre ce que l'on a déjà fait, et la mémoire est encore fraîche de pourquoi on a choisi telle ou telle opération. Mais parfois, il est bien utile de commenter les opérations afin de se rappeler plus tard de quoi il s'agissait. Surtout que, quand on débute avec awk ou sed, on procède par (de très nombreux) essais/erreurs, et avant de trouver la bonne ligne de code, documenter scrupuleusement chacune des versions qui vont mener à cette ligne de code est salutaire. Je l'ai fait assez spontanément, sur le mode du carnet de terrain que l'on remplit quand on est un peu perdu, le plus souvent en notant ce que je faisais dans un fichier .txt archivé à côté des données à traiter.
-
Collecter, nettoyer, traiter, documenter, tout cela se développait ensemble, mais restait l'affaire d'environnements bien distincts, entre l'éditeur de texte, les terminaux pour awk ou sed, et openrefine, etc. je connaissais l'existence de R, le logiciel de statistiques et modèle d'écologie opensource académique (cf.illustration, krkrkrkr...). Fort logiquement, les paquets de R se trouvant dans Debian, j'ai commencé à essayer des trucs pas trop ambitieux, à récupérer des one-liners ou des tutoriels qui étaient mieux expliqués pour R que pour
awketsed. Seulement, en plus de requérir l'apprentissage d'un nouveau langage alors que je ne maîtrisais déjà pas bien la syntaxe de awk, la syntaxe de R demandait à ce que les éléments (fonctions, arguments, etc.) soient insérés les uns dans les autres avec des tonnes de parenthèses enchâssées (cf.illustration). L'enchevêtrement visuel du code compliquait amplement la lisibilité des opérations, qui n'apparaissaient plus dans un ordre tout à fait linéaire, particulièrement sur le code un peu brouillon d'un débutant autodidacte dans mon genre.

mème fameux à propos des différents paradigmes des logiciels de statistiques
- Comment R et Rstudio ont-ils malgré cela pris le dessus ? C'est à l'occasion d'un job en freelance que j'ai découvert l'existence d'un autre versant de R, le tidyverse. Le tidyverse, c'est tout une série de paquets et de fonctions qui laissent de côté la syntaxe historique enchâssant les fonctions de R en pelures d'oignon (de l'intérieur vers l'extérieur) et mettent le pipe (cf. exemple dans le bloc de code suivant) au centre de la syntaxe du code afin de linéariser explicitement à l'écran l'écriture du code et sa documentation, son commentaire, ainsi que, à la fin, la lecture. #salvation ! Après des années d'errance entre tous ces outils, un ensemble satisfaisant pouvait se stabiliser et me servir à travailler, d'abord les données, mais aussi le récit de leur traitement, car Rstudio offrait en plus des outils merveilleux comme les notebooks et les fichiers en Rmarkdown, qui sont autant de manière de rédiger des rapports d'analyses contenant à la fois les données, le code, les graphiques et le texte structuré de l'analyse. On pouvait, ainsi équipé, organiser dès le début de la collecte des données la linéarisation de l'ensemble des étapes du raisonnement.
# syntaxe de base R pour enchaîner 4 opérations :
round(exp(diff(log(x))), 1)
# syntaxe tidyverse avec le pipe de magrittR pour les mêmes 4 opérations :
x %>% log() %>%
diff() %>%
exp() %>%
round(1)
## l'exemple provient de https://www.datacamp.com/community/tutorials/pipe-r-tutorial
Ce parcours d'anecdotes techniques offre des éléments pour comprendre la manière dont l'écriture du code sert la linéarisation du discours scientifique. Il me semble que l'on peut les synthétiser en trois sections : le principe des boîtes qui s'articulent et s'enchaînent, la documentation comme colonne vertébrale du récit scientifique, la corrigibilité (que ce mot est moche !) du code et de sa documentation, comme moyen de produire la linéarisation des opérations puis du discours.
Les fonctions comme des boîtes à aligner
Les fonctions de R sont, entre autres choses, des boîtes qui transforment une entrée en une sortie. 'Boîtes' n'est probablement pas une formule très rigoureuse informatiquement parlant, mais elle permet de saisir qu'une fois qu'on a idée de l'opération globale que permet la boîte, on n'a pas forcément besoin de l'ouvrir pour savoir ce qu'il y a dedans, du fait que, ce qui est d'abord intéressant c'est ce qui en sort, et non pas la façon dont on l'obtient. Évidemment, il arrivera toujours un moment où l'on finira par regarder le code d'une fonction, pour comprendre la manière dont celle-ci fonctionne et agit sur les données en entrée, pour l'adapter ou la corriger. Mais c'est une autre histoire, et comme on peut déplier une boîte, on peut la replier tout aussi bien sur elle même, et laisser son mécanisme caché, couvercle bien refermé.
Une fonction donne une direction par la transformation qu'elle opère sur les données qu'on indique en entrée de sa boîte, et de ce point de vue là, elles ont un rôle de vecteur opératoire. La répétition ou l'enchaînement de plusieurs fonctions à la suite les unes des autres se produit parce qu'on utilise l'output d'une fonction comme input de la fonction suivante. C'est par ce biais que l'on transforme un jeu de données relativement hétéroclite, incomplet, élaboré de manière inconsistante, en un jeu de données, souvent moins important, mais parfaitement structuré et exploitable pour l'analyse. Bien entendu, d'autres fonctions vont servir à la création de nouvelles variables, ainsi qu'à leur analyse, et elles suivent le même principe de boîtes noires et de vecteurs opératoires.
On a donc des boîtes/vecteurs, comme pour les puzzles, et tout ce que l'on peut se demander c'est : qu'est-ce qui doit aller avant ? Qu'est-ce qui doit aller ensuite ? Sous quelle forme doit arriver ce que l'on va passer dans telle boîte ? Que faire à partir de ce qui va sortir de la fonction-boite ? En quoi ces enchaînements de fonctions participent-ils en pratique de la structuration linéaire du raisonnement et du récit scientifique final ? Il est naïf de penser que l'on pourrait rédiger un script dans lequel on entrerait les "données brutes" et à la sortie duquel on trouverait le résultat de l'analyse. Si des chercheur·ses présentent malgré tout les choses sous cette forme-là, c'est souvent pour faciliter la compréhension de leur étude dans un temps imparti très court, car c'est une convention que de le réduire à à sa stricte synthèse linéaire. En somme c'est le produit final, et il ne reflète pas spécialement les milles circonvolutions de sa création.
Ce nettoyage des circonvolutions des impasses concrètes dans l'étude efface, le plus souvent, le fait que des hypothèses ont du être complètement reformulées, et que, au final, les résultats que l'on a jugés intéressants à présenter ne concernent pas la moitié des opérations effectivement engagées sur les données. Seulement, ce n'est pas un problème, Car une fois le raisonnement construit pour l'analyse, le redécoupage, pour répondre à un appel à communication par exemple, parfois même le recalcul rapide de quelques données supplémentaires, va se faire par rapport à cet élément linéaire central qu'est le code, la série d'opérations linéaires effectuées sur un jeu de données, ainsi que l'analyse qui en dérive. L'écriture du script, et a fortiori des notebooks en markdown qui mêlent scripts et analyse rédigée dans un même document, s'adapte à l'analyse qui, elle-même, se construit à partir du script. Au fur et à mesure de l'écriture des fonctions, s'insère l'écriture des analyses et du récit scientifique final.
Et tout cela se produit sur la feuille, à partir d'un langage qui est contraignant, pour ce qui concerne le script, et en un sens, organise les possibles analytiques, en en réduisant la variété, et en en structurant les éléments qui s'articulent très directement et concrètement aux opérations codées. Si, d'aventure, on peine à canaliser le foisonnement d'idées face à un terrain à étudier (ça arrive même aux meilleur·es :P), foisonnement qui peut être parfaitement stérile par la surcharge qu'il impose à la réflexion, écrire des petits scripts peut alors jouer un rôle d'exosquelette qui donne forme à la réflexion depuis l'extérieur. Le code devient alors l'instrument orthopédique de la linéarisation du traitement et de l'analyse des données. Et lui seul le permet, car dans un tableur, par exemple, à partir des mêmes données, la série d'opération se déploierait tout autrement dans l'espace de la grille du tableur, et ne s'écrirait ni se s'enregistrerait pas vraiment. Cela aurait deux conséquences essentielles : il manquerait le processus de documentation et la possibilité de corriger infiniment le travail déjà effectué, deux propriétés de l'écriture de scripts centrales dans la linéarisation du récit scientifique.
La documentation comme colonne vertébrale du raisonnement
Qu'est-ce que "documenter le code" ? Pour une ligne ou une portion de code, on va préciser, sur la ligne précédente, à quoi elle sert dans l'ensemble du script. Ce texte, palimpseste ou mode d'emploi embarqué, va être utile, aussi bien pour d'autres personnes que pour soi-même dans 6 mois ou dans 10 ans, à saisir quelle était l'intention initiale lors de l'écriture. La documentation, c'est donc très pratique, même si nombre de développeur·ses trouvent ça chiant à rédiger et superflu. Pour ma part, la fonction mémorielle s'est élargie à la documentation de l'ensemble de ce que je faisais autour du traitement des données. J'avais tendance à partir dans tous les sens, et parfois à ne plus savoir où revenir lorsqu'une piste s'avérait être une impasse. En documentant, chemin faisant, l'enchaînement des opérations que je tentais, bien que souvent dispersées, effectuées en parallèle ou bien en remplacement les unes des autres, j'ai pu toujours retrouver cette ligne directrice intuitivement engagée.
Il me semble qu'il existe des points communs importants entre le fait de documenter le parcours de l'ethnographe sur un terrain, ou le déroulement de n'importe quelle étude dans un laboratoire, et le fait de documenter le code que l'on écrit pour aider d'autres personnes ou bien soi-même, plus tard, à en comprendre l'intention et la logique. L'enseignement d'un premier cours "d'enquête par observation" en SHS devrait être le suivant : on prend des notes dans un carnet, page de droite pour décrire ce que à quoi l'on assiste, et page de gauche pour noter ses impressions, quitte à revenir dessus plus tard. Dans tous les cas, les notes comme les commentaires se superposent, se renvoient les uns aux autres, se corrigent aussi, jusqu'à permettre de revenir sur le chemin parcouru.
Prendre des notes, tout comme commenter le code, c'est matérialiser l'intention et ses conditions à un moment t et s'outiller pour externaliser la mémoire de tout le travail à effectuer. Ceci est donc valable dans un carnet de laboratoire ou de terrain tout autant que dans les interlignes "commentés" d'un script. La méthodologie d'une enquête n'est jamais la transcription d'un programme de recherche, au contraire, c'est un retour d'expérience, une considération a posteriori. Elle a donc besoin de ces notes et de ces commentaires au plus haut point. À ce sujet, il est intéressant de remarquer que pendant l'écriture d'un script, le commentaire est souvent rédigé avant de s'attaquer à la ligne de code, annonçant programmatiquement ce que la ligne de code devra réaliser. Il est tout aussi souvent corrigé juste après, ou alors beaucoup plus tard, lors du débugging, afin d'être contextualisé, précisé, éclairci, affiné.
Documenter mon code, aussi basique soit-il, m'a appris à mieux structurer les fichiers, à raconter le déroulé du traitement des données, etc. Surtout, cela m'a mis face au fait que nombre de moments de bascule dans mon exploration des données, nombre de fausses pistes ou de changements de stratégies passaient à la trappe de ma mémoire alors même qu'ils avaient eu un rôle temporairement prépondérant dans la forme que prenait l'analyse en cours. Documenter petit à petit a donc permit, paradoxalement, de mettre en évidence mes intuitions ainsi que leurs limites une fois testées. Sans commentaires, les intuitions et les milles petites choses très contextuelles que je comprenais disparaissaient au fur et à mesure que j'avançais pour trouver une solution en cherchant des conseils ou des modèles dans les handbooks ou sur stackoverflow.
Les notebooks combinant code et analyse rédigée en markdown sont importants de ce point de vue là : documenter le code, passe aussi par la rédaction des analyses relatives à chaque graphique, chaque tableau. Ceci permet de relancer les interrogations, si bien que le raisonnement se construit chemin faisant dans un même espace fonctionnel et visuel, sans que tout ne soit pour autant visuellement confondu. L'écriture en markdown, permet d'intercaler des blocs de texte entre les blocs de codes, eux-mêmes composés de lignes de code et de commentaires. De cette manière, les blocs en markdown s'avèrent documenter le code en faisant entrer l'analyse entre ses lignes et en matérialisant au fur et à mesure les conditions comme les productions du code. Au final, c'est un tressage de différents types de textes (code, commentaires, analyses et graphiques), qui ont tous leur linéarité propre, et dont la rédaction concomitante permet de composer une linéarité d'ensemble.
La corrigibilité comme linéarisation itérative
Ce qui a retourné le plus sauvagement mon cerveau à l'usage d'OpenRefine, c'est la possibilité de lire sous forme de code la suite d'opérations que l'on vient d'effectuer à la main. Lorsqu'on nettoie des données, il y a BEAUCOUP de minuscules opérations qui s'enchaînent : corriger la casse ici, changer les virgules en point-virgule là, séparer la 3ème colonne en deux nouvelles colonnes, mais seulement s'il y a deux mots, pas s'il y en a 1 seul ou trois, transformer le format de dates, vérifier si la colonne ainsi créée coïncide avec une autre, etc. Du coup, on chérit OpenRefine lorsque l'on peut corriger une erreur en plein milieu d'une série d'opérations et relancer cette série d'un seul clic. C'est largement plus efficace que le tableur, dans lequel on devra annuler toutes les opérations avec CTRL+Z, corriger l'erreur, puis refaire l'ensemble des opérations suivantes comme si de rien n'était (et sans se planter une seconde fois à un autre endroit !). Cette logique manuelle et dans un certain sens amnésique (malgré l'historique des opérations du tableur) est absolument intenable dans un workflow de nettoyage/formatage de données.
Il existe de nombreuses raisons de corriger du code dans la manipulation de données. Parfois on corrige un erreur, simplement pour que l'opération fonctionne, des fois on corrige le code d'une opération pour la réorienter vers une hypothèse différente ou bien pour l'articuler autrement avec l'opération précédente ou suivante. Construire une analyse ne consiste pas à suivre un programme pré-établit, il peut y en avoir un mais ça n'arrive jamais qu'on le suive à la lettre, ou alors, honnêtement, c'est qu'il y a besoin de s'interroger sur la collecte ou la question de recherche (parce que, même lors d'un suivi statistique longitudinal de populations ou d'événements, pour lesquels la méthode est largement rodée, il y a toujours un truc qui change ou qui n'était même pas prévisible...).
Le reste du temps, des éléments de réflexion, des pistes impromptues ou des réorientations soudainement évidentes vont s'arrimer à n'importe quelle partie du raisonnement, et ainsi le faire proliférer dans tous les sens en même temps (la fameuse "pensée en étoile" ou "pensée associative", etc.). C'est particulièrement le cas quand on fait du textmining, ou que l'on travaille à partir de données numériques collectées en ligne, car on ne sait que très rarement à quoi s'attendre exactement, même lorsqu'on connait bien la plateforme ou les thèmes abordés dans le corpus. C'est alors par une succession d'essais-erreurs et de corrections afférentes que l'on va avancer dans l'analyse. Le code permet alors l'élaboration d'un récit quasi-méthodologique linéaire, grâce à l'emboîtement des fonctions les unes après les autres, mais aussi en offrant l'occasion de construire petit à petit cette linéarité, non pas ex nihilo, mais par itérations et corrections régulières.
Cette canalisation du raisonnement n'est-elle pas une caractéristique que l'on vient d'attribuer aux fonctions-vecteurs ? Pas exactement... C'est tout le code comme processus d'écriture qui est en jeu cette fois-ci, et non pas le seul principe de sa syntaxe : on n'écrit pas du code de manière spontanément linéaire en posant d'abord la fonction A, puis la fonction B, puis la fonction C, même si celles-ci sont conçues pour ça. Certes les fonctions doivent et vont s'enchaîner les unes aux autres, mais encore faut-il savoir pourquoi les enchaîner. D'une certaine manière, c'est le texte du code comme document correctible donc, qui permet de produire de la linéarité au fur-et-à-mesure. On voit et on amende littéralement le code dans l'éditeur de texte, on peut rajouter quelque chose avant, déplacer un bloc de code plus loin, remonter corriger la transformation opérée sur une variable pour une raison x, parce qu'elle entre en conflit avec une transformation y plus impérieuse.
Avoir la possibilité de tester le code, de l'exécuter sans détruire les données, juste pour voir ce que ça donne est primordial. Si le calcul plante, on corrige. Si le résultat apparaît abscons, on trouve une autre manière de procéder. Avoir la possibilité de corriger autant de fois que nécessaire la chaîne qui emboîte les fonctions les unes après les autres, et transforme ainsi les données "brutes" en une analyse est à même d'offrir un récit linéaire consistant et long. On fait plein d'aller-retours, sauf que le processus de linéarisation est déjà matérialisé dans le code, le texte, et n'a pas besoin d'être forcément et systématiquement présent dans la pensée de celui ou celle qui y travaille, c'est-à-dire qu'on peut en oublier une partie, en la repliant sur elle-même (folding/unfolding), dès lors qu'elle fonctionne, par exemple, quitte à revenir dessus plus tard, si on l'a bien documentée.
Pour ouvrir ?
Je viens d'une époque où l'on découvrait l'usage du contrat doctoral, et où les formations méthodologiques des doctorant·es étaient essentiellement effectuées suivant la bonne volonté et les compétences des équipes disponibles dans les labos. Si les formations doctorales se sont largement systématisées et étoffées, il n'est pas certain que les petits mécanismes que j'ai tenté de décrire ici soient explicitement présentés, dans la mesure où ils apparaissent sûrement comme évidents et universellement intelligibles à certaines personnes, ou bien apparaissent comme totalement hors de propos à d'autres. Il me semble pourtant que même pour des rédacteur·rices expérimentées ces mécanismes externes d'ordonnancement restent intéressants à saisir, notamment à une époque où le travail interdisciplinaire se fait de plus en plus courant, en particulier avec l'articulation de workpackages aux méthodes qualitatives et quantitatives. Dans ce contexte, les multiples manières de raisonner et rédiger (analyses data-driven, interprétation, approches théoriciennes, etc.) requièrent de comprendre comment les "autres" travaillent pour produire des textes collectifs en leur compagnie et sans heurts. Comprendre que les outils de traitement des données, mais aussi de prise de note, de rédaction, etc., ont une importance dans la forme que prennent nos raisonnement est particulièrement intéressant à mettre en œuvre alors que les logiques identitaires liées aux approches méthodologiques en sciences sociales structurent toujours de nombreuses incompréhensions entre collègues.